stable-diffusion-3.5-large-turbo 是一种高精度文本到图像模型。
本指南将解释如何在 google colab 上设置和运行模型。
先决条件
访问拥抱脸。
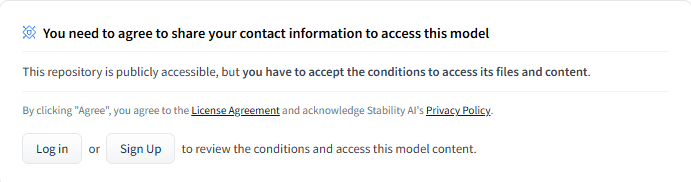
要使用 stable-diffusion-3.5-large-turbo,您需要一个 huggingface 帐户。
如果您还没有帐户,请创建一个帐户。
注册后,您将看到以下屏幕:

输入所需信息,您将立即获得模型的访问权限。
如果您想下载并使用该模型,您将需要访问令牌。从您的帐户页面创建一个:
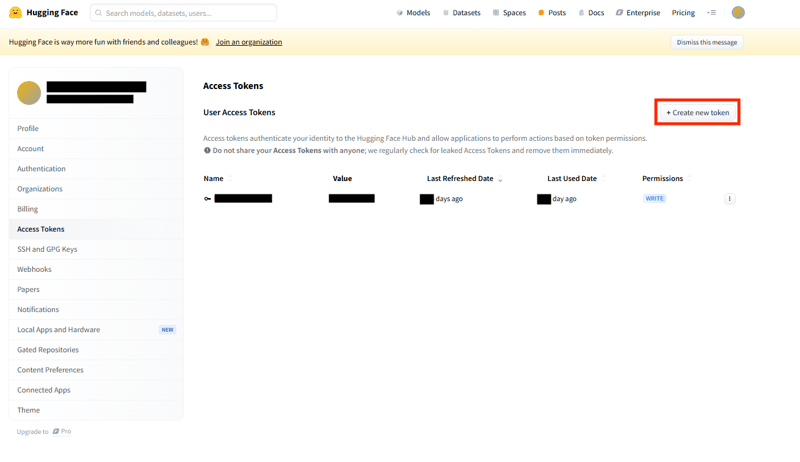
通过右上角的个人资料图标导航到您的帐户页面,转到访问令牌选项卡,然后选择创建新令牌来创建令牌。
运行代码
安装所需的库
首先,在 google colab 中安装必要的库:
!pip install --quiet -u transformers
-u 选项将库更新到最新版本,--quiet 禁止下载消息。
验证您的帐户
通过运行以下命令并输入您之前创建的令牌来验证您的 huggingface 帐户:
!huggingface-cli login
下载模型
使用以下 python 代码加载并设置模型:
import torch
from diffusers import stablediffusion3pipeline
pipe = stablediffusion3pipeline.from_pretrained("stabilityai/stable-diffusion-3.5-large-turbo", torch_dtype=torch.bfloat16)
pipe = pipe.to("cuda")
注意:该模型消耗约 27gb 内存。
生成图像
通过运行此代码来生成图像来测试设置:
prompt = "a capybara holding a sign that reads hello fast world"
save_filename = "capybara.png"
image = pipe(
prompt,
num_inference_steps=4,
guidance_scale=0.0,
).images[0]
您可以在 diffusers github 文档中找到这些参数的解释。
保存并显示生成的图像:
image.save(save_filename) image

以上就是如何在 Google Colab 上运行 stable-diffusion--large-turbo的详细内容,更多请关注php中文网其它相关文章!
版权声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系 yyfuon@163.com




