请我喝杯咖啡☕
*备忘录:
- 我的文章解释了梯度消失问题、梯度爆炸问题和 ReLU 死亡问题。
- 我的文章解释了 PyTorch 中的层。
- 我的文章解释了 PyTorch 中的激活函数。
- 我的文章解释了 PyTorch 中的损失函数。
- 我的文章解释了 PyTorch 中的优化器。
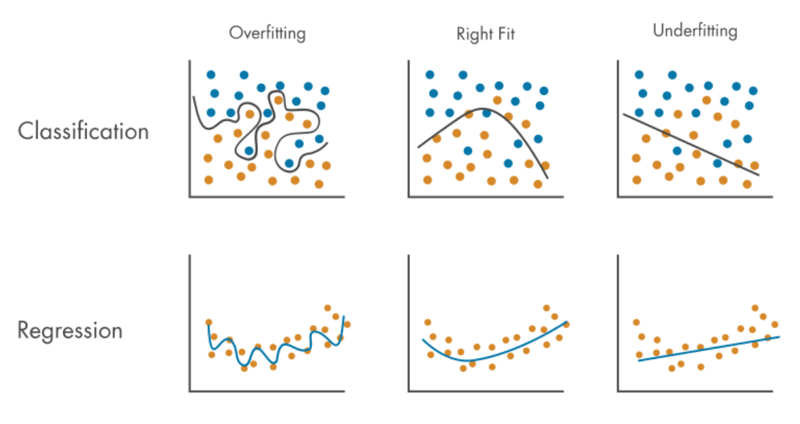
*过拟合和欠拟合都可以通过Holdout方法或交叉验证(K-Fold Cross-Validation)来检测。 *交叉验证更好。
过拟合:
- 问题是模型对训练数据的预测准确率很高,但对新数据(包括测试数据)的预测却很少,因此模型对训练数据的拟合程度比对新数据的拟合程度要高。
- 发生的原因是:
- 训练数据很小(不够),因此模型只能学习少量模式。
- 训练数据是不平衡的(有偏差的),有很多特定的(有限的)、相似或相同的数据,但没有很多不同的数据,因此模型只能学习少量的模式。
- 训练数据有很多噪声(噪声数据),因此模型会学习很多噪声的模式,但不会学习正常数据的模式。 *噪声(噪声数据) 表示离群值、异常或有时重复的数据。
- 训练时间过长,epoch数过多。
- 模型太复杂。
- 可以通过以下方式缓解:
- 更大的列车数据。
- 拥有大量各种数据。
- 减少噪音。
- 打乱数据集。
- 提前停止训练。
- 集成学习。
- 正则化以降低模型复杂性:
*备注:
- 有Dropout(正则化)。 *我的帖子解释了 Dropout 层。
- L1 正则化也称为 L1 范数或套索回归。
- L2 正则化也称为 L2 范数或岭回归。
- 我的帖子解释了 linalg.norm()。
- 我的帖子解释了 linalg.vector_norm()。
- 我的帖子解释了 linalg.matrix_norm()。
欠拟合:
- 是模型无法对训练数据和新数据(包括测试数据)进行准确预测的问题,因此模型无法同时拟合训练数据和新数据。
- 发生的原因是:
- 模型太简单(不够复杂)。
- 训练时间太短,epoch数太少。
- 应用了过度正则化(Dropout、L1 和 L2 正则化)。
- 可以通过以下方式缓解:
- 增加模型复杂性。
- 通过更多的 epoch 来增加训练时间。
- 减少正则化。
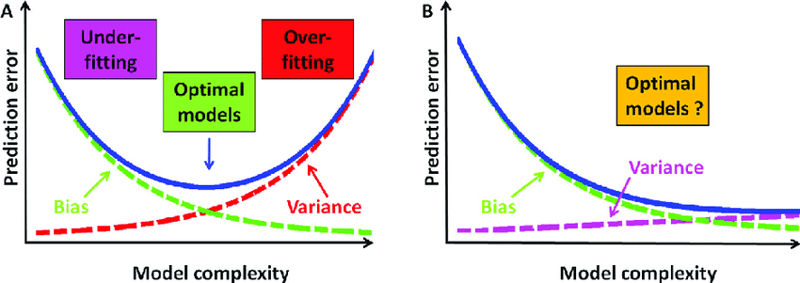
过拟合和欠拟合是权衡的:
过多的过拟合缓解(5.、6. 和 7.)会导致高偏差和低方差的欠拟合,而过多的欠拟合缓解( 1.、2. 和 3.)会导致低偏差和高方差的过度拟合,因此应平衡它们的缓解措施,如下所示:
*备忘录:
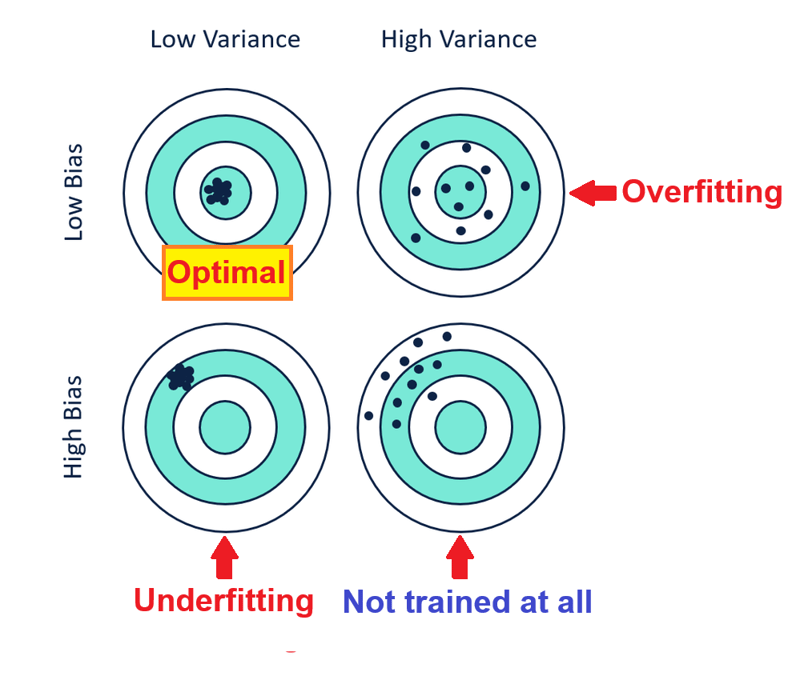
- 你也可以说偏差和方差是权衡的因为减少偏差会增加方差,而减少方差会增加偏差,因此它们应该是平衡的。 *增加模型复杂性会减少偏差,但会增加方差,同时降低模型复杂性会减少方差,但会增加偏差。
- 低偏差意味着高精度,高偏差意味着低精度。
- 低方差意味着高精度,高方差意味着低精度。
以上就是过拟合与欠拟合的详细内容,更多请关注php中文网其它相关文章!
版权声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系 yyfuon@163.com