在本文中,我将简要介绍一些最佳实践,这些最佳实践在使用 alembic 和 sqlalchemy 时帮助保持项目有序、简化数据库维护并防止常见陷阱。这些技巧不止一次地让我摆脱了麻烦。以下是我们将介绍的内容:
- 命名约定
- 按日期对迁移进行排序
- 表、列和迁移注释
- 无模型迁移中的数据处理
- 迁移测试(楼梯测试)
- 运行迁移的服务
- 对模型使用 mixins
1. 命名约定
sqlalchemy 允许您设置命名约定,在生成迁移时自动应用于所有表和约束。这使您无需手动命名索引、外键和其他约束,从而使数据库结构可预测且一致。
要在新项目中进行设置,请向基类添加约定,以便 alembic 将自动使用所需的命名格式。以下是在大多数情况下都有效的约定示例:
from sqlalchemy import metadata
from sqlalchemy.orm import declarativebase
convention = {
'all_column_names': lambda constraint, table: '_'.join(
[column.name for column in constraint.columns.values()]
),
'ix': 'ix__%(table_name)s__%(all_column_names)s',
'uq': 'uq__%(table_name)s__%(all_column_names)s',
'ck': 'ck__%(table_name)s__%(constraint_name)s',
'fk': 'fk__%(table_name)s__%(all_column_names)s__%(referred_table_name)s',
'pk': 'pk__%(table_name)s',
}
class basemodel(declarativebase):
metadata = metadata(naming_convention=convention)
2. 按日期对迁移进行排序
alembic 迁移文件名通常以修订标签开头,这可以使目录中的迁移顺序显得随机。有时按时间顺序排列它们很有用。
alembic 允许使用 file_template 设置在 alembic.ini 文件中自定义迁移文件名模板。以下是两种方便的命名格式,可让迁移保持井井有条:
- 基于日期:
file_template = %%(year)d-%%(month).2d-%%(day).2d_%%(rev)s_%%(slug)s
- 基于 unix 时间戳:
file_template = %%(epoch)d_%%(rev)s_%%(slug)s
在文件名中使用日期或 unix 时间戳可以使迁移保持井井有条,使导航更容易。我更喜欢使用 unix 时间戳,下一节将提供一个示例。
3. 表和迁移的注释
对于在团队中工作的人来说,注释属性是一个很好的做法。对于 sqlalchemy 模型,请考虑直接向列和表添加注释,而不是依赖文档字符串。这样,注释在代码和数据库中都可用,使 dba 或分析师更容易理解表和字段的用途。
class event(basemodel):
__table_args__ = {'comment': 'system (service) event'}
id: mapped[uuid.uuid] = mapped_column(
uuid(as_uuid=true),
primary_key=true,
comment='event id - pk',
)
service_id: mapped[int] = mapped_column(
sa.integer,
sa.foreignkey(
f'{integrationservicemodel.__tablename__}.id',
ondelete='cascade',
),
nullable=false,
comment='fk to integration service that owns the event',
)
name: mapped[str] = mapped_column(
sa.string(256), nullable=false, comment='event name'
)
为迁移添加注释也很有帮助,以便更容易在文件系统中找到它们。生成迁移时可以使用 -m
1728372261_c0a05e0cd317_add_integration_service.py 1728372272_a1b4c9df789d_add_user.py 1728372283_f32d57aa1234_update_order_status.py 1728372294_9c8e7ab45e11_create_payment.py 1728372305_bef657cd9342_remove_old_column_from_users.py
4. 避免在迁移中使用模型
模型通常用于数据操作,例如将数据从一个表传输到另一个表或修改列值。但是,如果模型在创建迁移后发生更改,则在迁移中使用 orm 模型可能会导致问题。在这种情况下,基于旧模型的迁移在执行时将会中断,因为数据库架构可能不再与当前模型匹配。
迁移应该是静态的并且独立于模型的当前状态,以确保无论代码如何更改都能正确执行。以下是避免使用模型进行数据操作的两种方法。
- 使用原始 sql 进行数据操作:
def upgrade():
op.execute(
"update user_account set email = concat(username, '@example.com') where email is null;"
)
def downgrade():
op.execute(
"update user_account set email = null where email like '%@example.com';"
)
- 直接在迁移中定义表: 如果想使用sqlalchemy进行数据操作,可以直接在迁移中手动定义表。这确保了迁移执行时的静态模式,并且不会依赖于模型中的更改。
from sqlalchemy import table, column, string
def upgrade():
# define the user_account table to work with data
user_account = table(
'user_account',
column('id'),
column('username', string),
column('email', string)
)
# get a connection to the database
conn = op.get_bind()
# select all users without an email
users = conn.execute(
user_account.select().where(user_account.c.email == none)
)
# update email for each user
for user in users:
conn.execute(
user_account.update().where(
user_account.c.id == user.id
).values(
email=f"{@example.com">user.username}@example.com"
)
)
def downgrade():
user_account = table(
'user_account',
column('id'),
column('email', string)
)
conn = op.get_bind()
# remove email for users added in the upgrade
conn.execute(
user_account.update().where(
user_account.c.email.like('%@example.com')
).values(email=none)
)
5. 迁移测试的阶梯测试
阶梯测试涉及逐步测试升级/降级迁移,以确保整个迁移链正常工作。这确保每次迁移都可以成功地从头开始创建新数据库并降级而不会出现问题。将此测试添加到 ci 对于团队来说非常宝贵,可以节省时间并减少挫败感。
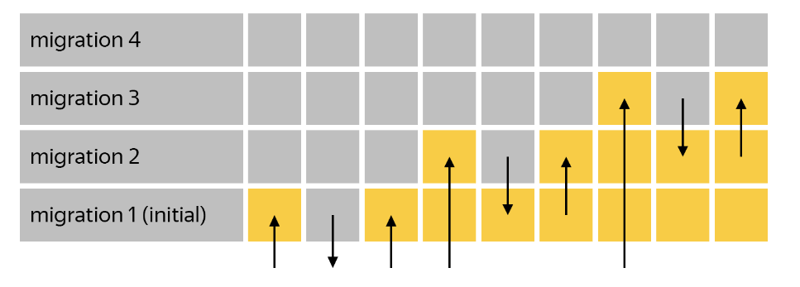
将测试集成到您的项目中可以轻松快速地完成。您可以在此存储库中找到代码示例。它还包括其他可能有帮助的有价值的迁移测试。
6. 迁移服务
用于执行迁移的单独服务。这只是执行迁移的一种方法。当在本地或类似开发的环境中开发时,这种方法非常适合。我想提醒您有关条件 dependent_on 功能,该功能与此处相关。我们使用 alembic 获取应用程序映像并在单独的容器中运行它。我们添加对数据库的依赖关系,条件是仅当数据库准备好处理请求(service_healthy)时才开始迁移。此外,可以为应用程序添加条件依赖项(service_completed_successively),确保它仅在迁移成功完成后启动。
db:
image: postgres:15
...
healthcheck:
test: ["cmd-shell", "pg_isready -u ${postgres_user} -d ${postgres_db}"]
interval: 10s
start_period: 10s
app_migrations:
image: <app-image>
command: [
"python",
"-m",
"alembic",
"-c",
"<path>/alembic.ini",
"upgrade",
"head"
]
depends_on:
db:
condition: service_healthy
app:
...
depends_on:
app_migrations:
condition: service_completed_successfully
</path></app-image>
depends_on 条件确保迁移仅在数据库完全准备好后运行,并且应用程序在迁移完成后启动。
7. 模型的 mixins
虽然这可能是显而易见的一点,但重要的是不要忽视它。使用 mixins 是避免代码重复的便捷方法。 mixin 是包含常用字段和方法的类,可以将其集成到需要的任何模型中。例如,我们经常需要created_at和updated_at字段来跟踪记录的创建和更新时间。使用基于 uuid 的 id 来标准化主键也很有用。所有这些都可以封装在 mixin 中。
import uuid
from sqlalchemy import column, datetime, func
from sqlalchemy.dialects.postgresql import uuid
class timestampmixin:
created_at = column(
datetime,
server_default=func.now(),
nullable=false,
comment="record creation time"
)
updated_at = column(
datetime,
onupdate=func.now(),
nullable=true,
comment="unique record identifier"
)
class uuidprimarykeymixin:
id = column(
uuid(as_uuid=true),
primary_key=true,
default=uuid.uuid4,
comment="unique record identifier"
)
通过添加这些 mixins,我们可以在需要的任何模型中包含 uuid id 和时间戳:
class User(UUIDPrimaryKeyMixin, TimestampMixin, BaseModel):
__tablename__ = 'user'
# Other columns...
结论
处理迁移可能具有挑战性,但遵循这些简单的做法有助于保持项目井然有序且易于管理。命名约定、日期排序、注释和测试使我免于混乱并有助于防止错误。我希望这篇文章对您有所帮助——请随时在评论中分享您自己的迁移技巧!
以上就是Alembic 和 SQLAlchemy 的最佳实践的详细内容,更多请关注php中文网其它相关文章!